
New to AppSync? Check out this Ultimate Guide to AWS AppSync
- Part 1: GraphQL endpoints with API Gateway + AWS Lambda (this post)
- Part 2: AppSync Backend: AWS Managed GraphQL Service
- Part 3: AppSync Frontend: AWS Managed GraphQL Service
Introduction
Over the last four years, I've been exploring the world of big data, building real-time and batch systems at scale. For the last couple of months, I've been developing products with serverless architectures here at Glassdoor.
Given the intersection of serverless and big data, there have been a few questions on everyone's mind:
- How can we build low latency APIs to serve complex, high dimensional and big datasets?
- Using a single query, can we construct a nested response from multiple data sources?
- Can we build an endpoint which can securely aggregate and paginate through data and with high performance?
- And is there a way we can do all of that at scale, paying only for each query execution, and not for idle CPU time?
The answer for us ended up largely being GraphQL.
This post aims to show you how you too can streamline your existing workflow and handle complexity with ease. While I won't be digging deep into specific things Glassdoor was working on, I will be showing you a pretty related example that utilizes a mini Twitter clone I made.
Ready to talk about creating Serverless GraphQL endpoints using DynamoDB, RDS and the Twitter REST API? Ready to see a sweet performance comparison? Ready to hear some solid techniques on how you can convince the backend team that using GraphQL is a great idea?
Awesome. Let's go.
Note For the GraphQL and Serverless primer, keep reading. Or click here to go straight to the code walkthrough
What is GraphQL?
I’m going to start this off by stating a fact: The way we currently build APIs, as a collection of micro-services that are all split up and maintained separately, isn’t optimal. If you're a fellow back-end or front-end engineer, you're probably familiar with this struggle.
Luckily for us, the tech horizon is ever-expanding. We have options. And we should use them.
GraphQL lets you shrink your multitude of APIs down into a single HTTP endpoint, which you can use to fetch data from multiple data sources.
In short, it lets you:
- Reduce network costs and get better query efficiency.
- Know exactly what your response will look like and ensure you're never sending more or less than the client needs.
- Describe your API with types that map your schema to existing backends.
Thousands of companies are now using GraphQL in production with the help of open source frameworks built by Facebook, Apollo, and Graphcool. Starbucks uses it to power their store locator. When I read that, it made my morning coffee taste even better. 😉

Very reasonably, you are probably thinking, “Yeah, okay, Facebook is one thing; they have a giant engineering team. But for me, having only one API endpoint is too risky. What if it goes down? How do I handle that much load? What about security?”
You are absolutely correct: with one HTTP endpoint, you need to be entirely sure that endpoint never goes down and that it scales on demand.
That’s where serverless comes in.
What is Serverless?
Serverless has gained popularity over last few years, primarily because it gives developers flexibility.
With Serverless comes the following:
- No server management (no need to manage any form of machine)
- Pay-per-execution (never pay for idle)
- Auto-scale (scale based on demand)
- Function as a unit of application logic
What makes Serverless and GraphQL such a great fit?
When moving to GraphQL, you suddenly rely on one HTTP endpoint to connect your clients to your backend services. Once you do decide to do that, you want this one HTTP endpoint to be: reliable, fast, auto-scaling and have a small attack vector regarding security.
All these properties are fulfilled by a single AWS Lambda function in combination with an API Gateway. It’s just a great fit!
In sum, powering your GraphQL endpoint with a serverless backend solves scaling and availability concerns outright, and it gives you a big leg up on security. It’s not even that much code or configuration.
It takes only a few minutes to get to a production-ready setup, which we're about to dive into, right now.
Serverless-GraphQL repository
With the shiny new Serverless and GraphQL Repository, it’s incredibly straightforward to get your HTTP endpoint up and running.

The repository comes in two flavors: API Gateway + Lambda backend, or AppSync backend. (More backend integrations, including Graphcool Prisma, Druid, MongoDB, and AWS Neptune, forthcoming.)
Note: I’m going to focus on AWS Lambda below, but know that you can use any serverless provider (Microsoft Azure, Google Cloud Functions, etc.) with GraphQL.
Let's create a Serverless GraphQL Endpoint
To create this endpoint, I'm going to be using the Apollo-Server-Lambda package from npm. (You can also use Express, Koa, or Hapi frameworks but I prefer less complexity and more simplicity). Also, to make your endpoint production ready, you might want to integrate the lambda function with Cloudwatch-metrics, AWS X-Ray or Apollo Engine for monitoring and debugging.
Some of the main components of building your endpoint are (with links to serverless-graphql repo):
-
handler.js: lambda function handler to route HTTP requests and return the response.
-
serverless.yml: creates AWS resources and sets up the GraphQL endpoint.
-
schema.js: defines our GraphQL schema we're using to build this mini Twitter app.
-
resolver.js: defines query handler functions to fetch data from our other services (RDS, REST, DynamoDB, etc.).
Step 1: Configure the Serverless template
We'll be using the Serverless Framework to build and deploy your API resources quickly. If you don't have the Framework installed, get it with npm install serverless -g.
To start, specify in your serverless.yml that you are setting up a GraphQL HTTP endpoint:
functions:
graphql:
handler: handler.graphqlHandler
events:
- http:
path: graphql
method: post
cors: true
Now, any HTTP POST event on the path /graphql will trigger the graphql Lambda function, and will be handled by graphqlHandler.
Step 2: Configure the Lambda function (Apollo-Server-Lambda)
Set up the callback to Lambda in your handler.js file:
import { graphqlLambda, graphiqlLambda } from 'apollo-server-lambda';
import { makeExecutableSchema } from 'graphql-tools';
import { schema } from './schema';
import { resolvers } from './resolvers';
const myGraphQLSchema = makeExecutableSchema({
typeDefs: schema,
resolvers,
});
exports.graphqlHandler = function graphqlHandler(event, context, callback) {
function callbackWithHeaders(error, output) {
// eslint-disable-next-line no-param-reassign
output.headers['Access-Control-Allow-Origin'] = '*';
callback(error, output);
}
const handler = graphqlLambda({ schema: myGraphQLSchema });
return handler(event, context, callbackWithHeaders);
};
In your Lambda function, GraphQL Schema and Resolvers will be imported (as I'll explain further in a minute).
Once API Gateway triggers an event, the graphqlLambda function will handle it. The response is sent back to the client.
Step 3: Create a GraphQL schema
For this post, I am going to focus on a subset of the schema to keep things simple—I'll handle mutations and subscriptions in a future post:
type Query {
getUserInfo(handle: String!): User!
}
type Tweet {
tweet_id: String!
tweet: String!
handle: String!
created_at: String!
}
type TweetConnection {
items: [Tweet!]!
nextToken: String
}
type User {
name: String!
description: String!
followers_count: Int!
following: [String!]!
topTweet: Tweet
tweets(limit: Int!, nextToken: String): TweetConnection
}
Step 4: Create your GraphQL resolvers
Still with me? Great. Let's dive deep into how Lambda retrieves data from DynamoDB, RDS and, the REST backend.
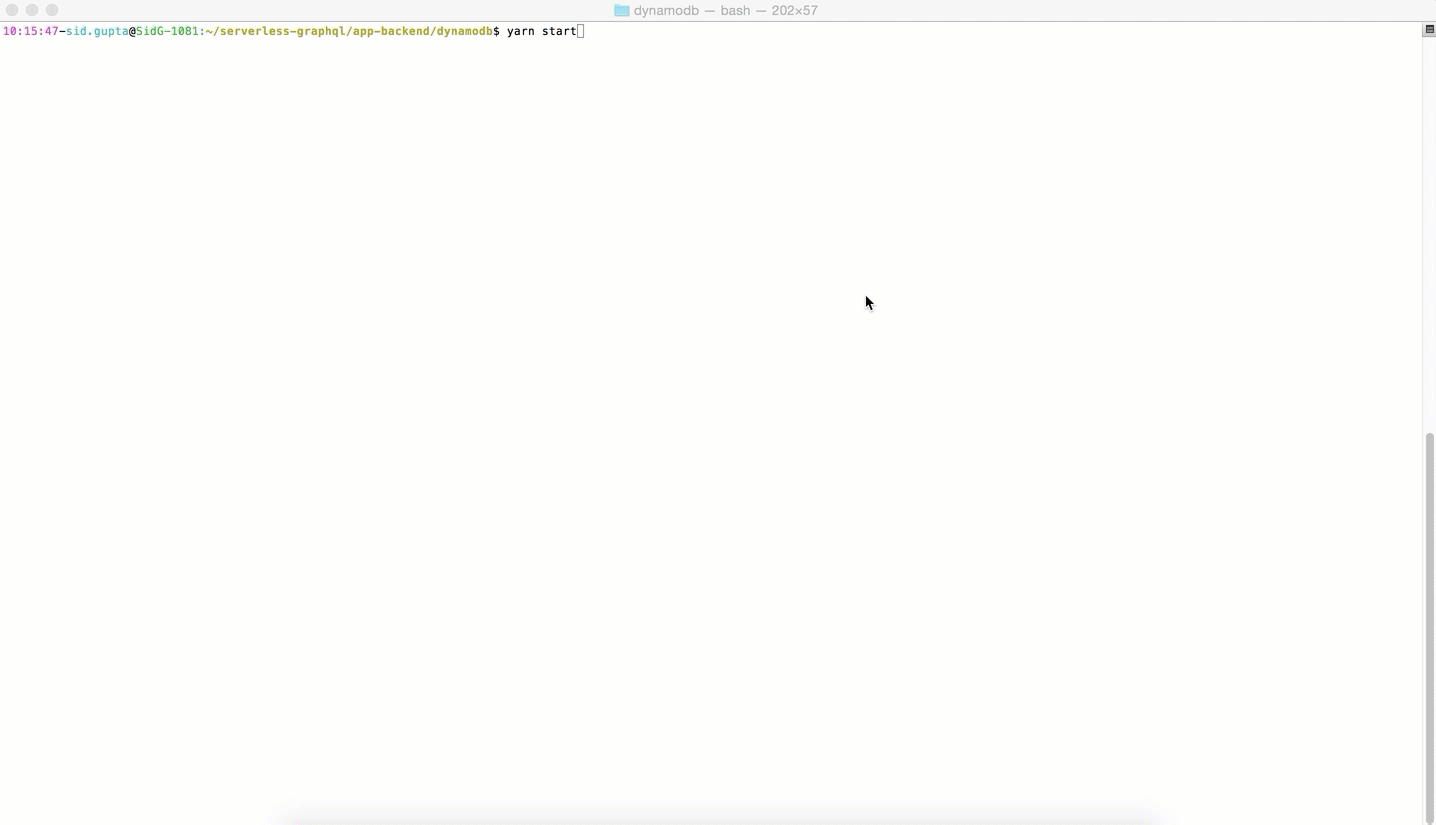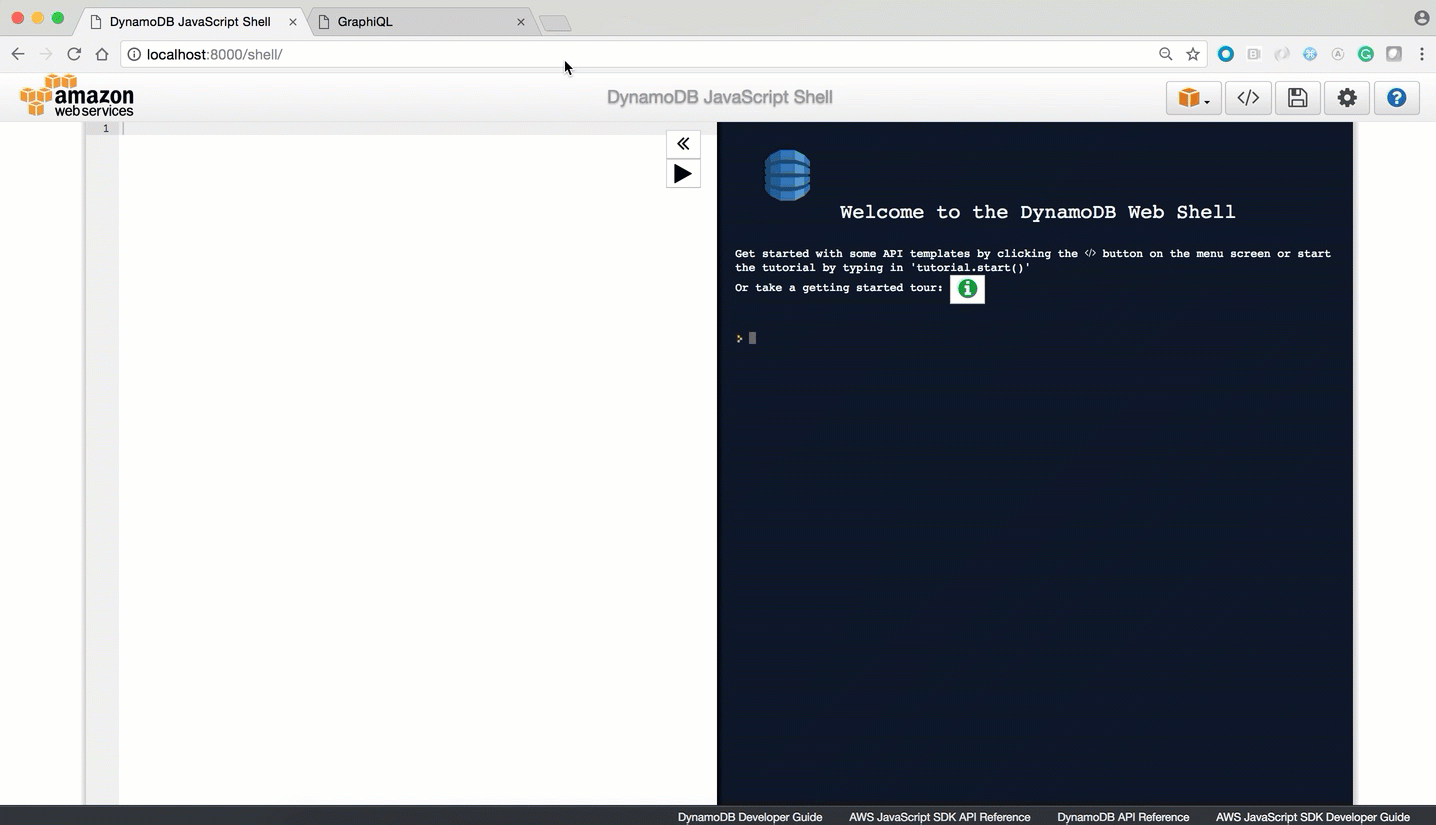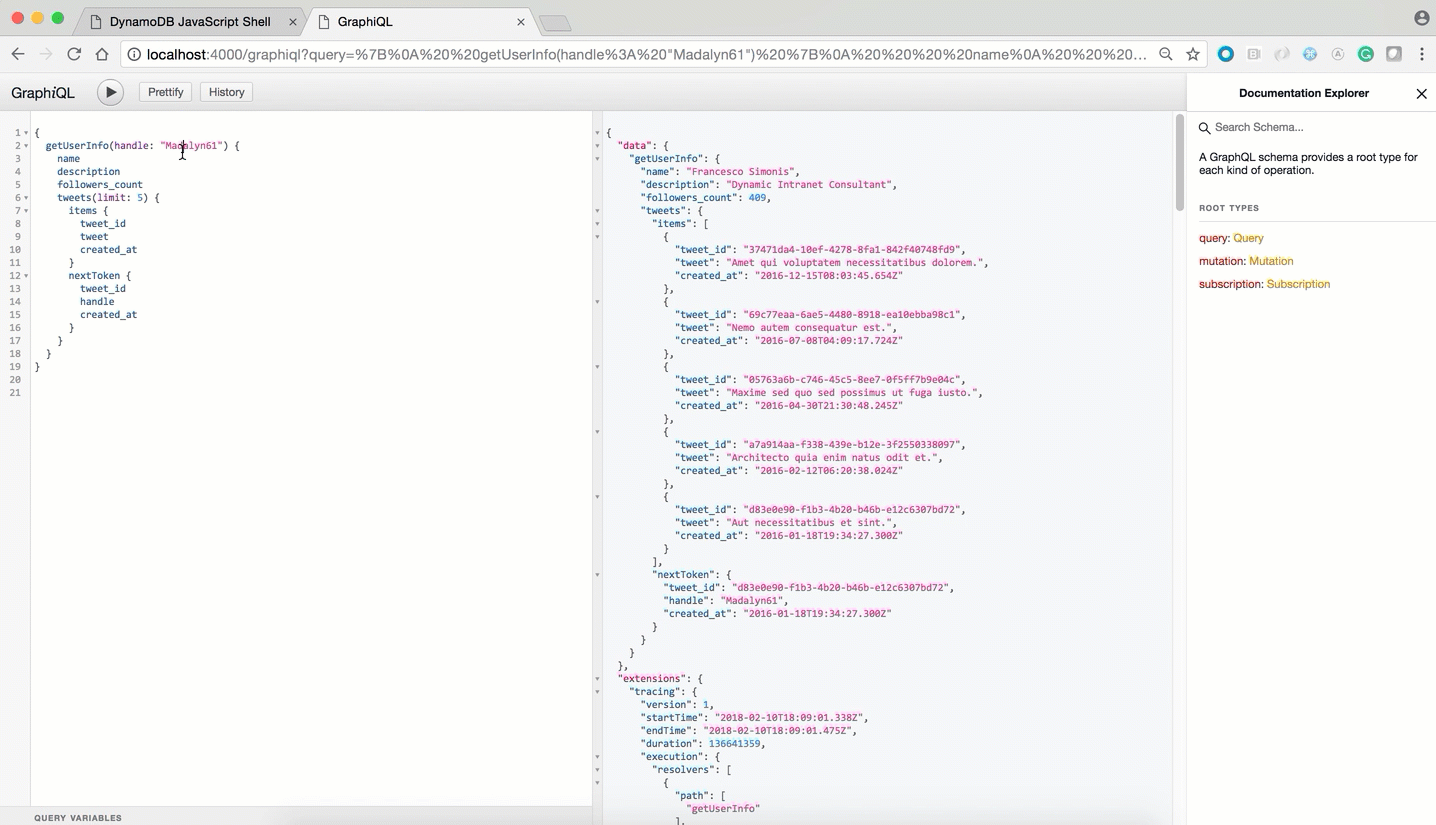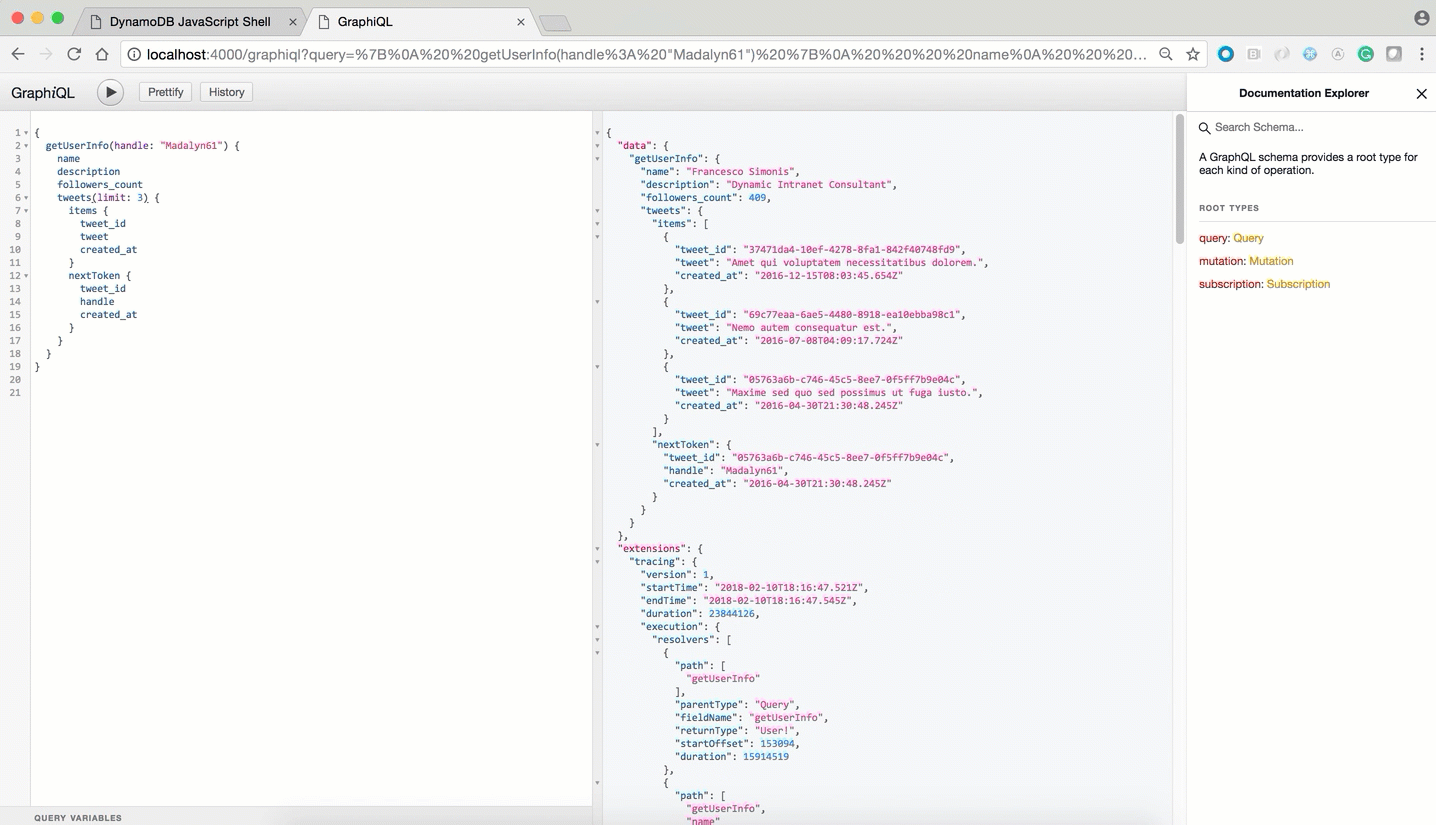
We'll use the getUserInfo field as an example. This field takes a Twitter handle as input and returns that user's personal and tweet info.
Setting up the DynamoDB backend
First, we'll create two tables (Users and Tweets) to store user and tweet info respectively. We'll also be using Global Secondary Index (tweet-index) on Tweets table to sort all user tweets by timestamp.
These resources will be created using the serverless.yml:
Table: User HashKey: handle Attributes: name, description, followers_count
Table: Tweets HashKey: tweet_id Attributes: tweet, handle, created_at Index: tweet-index (hashKey: handle, sortKey: created_at)
At this point, you'll need to mock fake data using Faker.
You'll also need to make sure your IAM Roles are set properly in the serverless.yml, so that Lambda can access DynamoDB. These are defined in the serverless.yml file in the repository.
If you're interested in knowing more about IAM permissions, here's an excellent primer.
Creating the GraphQL resolver
Let's set it up for getUserInfo to retrieve data from DynamoDB. I'll be breaking down the code for you.
First of all, we need to define how the getUserInfo and tweets fields will fetch the data:
export const resolvers = {
Query: {
getUserInfo: (root, args) => getUserInfo(args),
},
User: {
tweets: (obj, args) => getPaginatedTweets(obj.handle, args),
},
};
Then we'll query the DynamoDB table index, tweet-index, to retrieve paginated tweets for a given user handle. Passing the nextToken parameter implies paginating through the result set, which is passed as ExclusiveStartKey.
If the result contains LastEvaluatedKey (as shown here), then return it as nextToken:
getPaginatedTweets(handle, args) {
return promisify(callback => {
const params = {
TableName: 'Tweets',
KeyConditionExpression: 'handle = :v1',
ExpressionAttributeValues: {
':v1': handle,
},
IndexName: 'tweet-index',
Limit: args.limit,
ScanIndexForward: false,
};
if (args.nextToken) {
params.ExclusiveStartKey = {
tweet_id: args.nextToken.tweet_id,
created_at: args.nextToken.created_at,
handle: handle,
};
}
docClient.query(params, callback);
})
//then parse the result
},
For the getUserInfo field, you can similarly retrieve the results as shown below:
getUserInfo(args) {
return promisify(callback =>
docClient.query(
{
TableName: 'Users',
KeyConditionExpression: 'handle = :v1',
ExpressionAttributeValues: {
':v1': args.handle,
},
},
callback
)
)
//then parse the result
}
The end result? You've got a GraphQL endpoint that reliably scales! 💥
Let's test it out locally and then deploy it to production.
Clone the Git repo and install dependencies
git clone https://github.com/serverless/serverless-graphql.git
cd app-backend/dynamodb
yarn install
To test the GraphQL endpoint locally on my machine, I'm using these three plugins for the Serverless Framework: Serverless Offline, Serverless Webpack and Serverless DynamoDB Local.
These plugins make it super easy to run the entire solution E2E locally without any infrastructure. It will also help us debug issues faster.
If you've followed me this far, DynamoDB will now be available and running on your local machine at http://localhost:8000/shell:
For deploying your endpoint in production, please run:
cd app-backend/dynamodb
yarn deploy-prod
Note: We also have a previous post on making a serverless GraphQL API, which covers the process in more detail.
Setting up the RDS backend
DynamoDB is great for fetching data by a set of keys; but using a relational database like RDS will provide us the flexibility to model complex relationships and run aggregation mechanisms at runtime.
Let's look at the process of connecting your Lambda to RDS.
We have explained the requirements to set up RDS in production in the readme, but you can test your GraphQL endpoint locally using SQLite3 (without any AWS infrastructure). Boom!
Data modeling and table creation
We will create two tables (Users and Tweets) to store user and tweet info respectively, as described here.
Table: User Primary Key: user_id Attributes: name, description, followers_count
Table: Tweets Primary Key: tweet_id Attributes: tweet, handle, created_at, user_id
Then, you'll need to use Faker again to mock some fake data.
Set your Lambda in the same VPC as RDS for connectivity, and configure knexfile for database configuration in development and production environment.
(The serverless-graphql repo supports connecting to SQLite, MySQL, Aurora, or Postgres using Knex configurations—a powerful query builder for SQL databases and Node.js.)
const pg = require('pg');
const mysql = require('mysql');
module.exports = {
development: {
client: 'sqlite3', // in development mode you can use SQLite
connection: {
filename: './dev.db',
},
},
production: {
client: process.env.DATABASE_TYPE === 'pg' ? 'pg' : 'mysql', // in production mode you can use PostgresQL, MySQL or Aurora
connection: process.env.DATABASE_URL,
},
};
Let's go ahead and write our resolver functions.
The knex ORM layer queries the User table to resolve getUserInfo and returns a list of user attributes. Then, we join both Tweets and Users tables on user_id to resolve tweets. In the end, topTweet is returned using where, limit and orderBy clauses.
And it just works!
Here's the getUserInfo resolver:
export const resolvers = {
Query: {
getUserInfo: (root, args) =>
knex('Users')
.where('handle', args.handle)
.then(users => {
const user = users[0];
if (!user) {
throw new Error('User not found');
}
return user;
})
}
};
Here's the tweets resolver:
User: {
tweets: obj =>
knex
.select('*')
.from('Tweets')
.leftJoin('Users', 'Tweets.user_id', 'Users.user_id')
.where('handle', obj.handle)
.then(posts => {
if (!posts) {
throw new Error('User not found');
}
tweets = { items: posts };
return tweets;
}),
},
And here's the topTweet resolver:
User: {
topTweet: obj =>
knex('Tweets')
.where('handle', obj.handle)
.orderBy('retweet_count', 'desc')
.limit(1)
.then(tweet => {
if (!tweet) {
throw new Error('User not found');
}
return tweet[0];
}),
},
Run it locally on your machine (RDS instance not required).
Kickstart on local using SQLite
cd app-backend/rds
yarn install
yarn start
And deploy to production:
cd app-backend/rds
yarn deploy-prod
Note: When running in production, please make sure your database endpoint is configured correctly in config/security.env.prod.
REST wrapper
Last but not least—it's time for the REST API backend!
This use case is the most common when you have pre-existing microservices, and you want to wrap them around GraphQL. Don't worry; it's easier than you think.
We'll fetch data from Twitter's REST API, but it could very well be your own REST API. You'll need to create OAuth tokens here, OR use these test account tokens for faster setup.
In this case, we don't need to create tables or mock data because we will be querying real data. Let's look at how to resolve following field to find a list of Users being followed.
The consumerKey, consumerSecret and handle are passed as an input to the friends/list API:
import { OAuth2 } from 'oauth';
const Twitter = require('twitter');
async function getFollowing(handle, consumerKey, consumerSecret) {
const url = 'friends/list';
const oauth2 = new OAuth2(
consumerKey,
consumerSecret,
'https://api.twitter.com/',
null,
'oauth2/token',
null
);
return new Promise(resolve => {
oauth2.getOAuthAccessToken(
'',
{
grant_type: 'client_credentials',
},
(error, accessToken) => {
resolve(accessToken);
}
);
})
.then(accessToken => {
const client = new Twitter({
consumer_key: consumerKey,
consumer_secret: consumerSecret,
bearer_token: accessToken,
});
const params = { screen_name: handle };
return client
.get(url, params)
//then parse the result
}
Note: A complete example is given here. You can also check out Saeri's walkthrough on building a Serverless GraphQL Gateway on top of a 3rd Party REST API.
Go ahead and run it locally on your machine:
cd app-backend/rest-api
yarn install
yarn start
And deploy to production:
cd app-backend/rest-api
yarn deploy-prod
Client Integrations (Apollo ReactJS, Netlify, and S3)
The serverless-graphql repository comes with two client implementations
If you are new to the ReactJs + Apollo Integration, I would recommend going through these tutorials.
The code for apollo-client in the serverless-graphql repo is here.
To start the client on local, first start any backend service on local. For example:
cd app-backend/rest-api
yarn install
yarn start
Now, make sure http://localhost:4000/graphiql is working.
If you kickstart Apollo Client (as shown below), you will have a react server running on your local machine. The setup is created using create react app:
cd app-client/apollo-client
yarn install
yarn start

In production, you can also deploy the client on Netlify or AWS S3. Please follow the instructions here.
Performance Analysis
Which brings us to the best part. Let's dive into the performance of our Serverless GraphQL endpoint.
We can measure the E2E latency of the API call by adding the network delay, AWS API Gateway response time, and AWS Lambda execution time, which includes execution time of the backend query. For this analysis, my setup consists of:
Baseline Dataset: 500 Users, 5000 Tweets (10 tweets per user) where each user record is less than 1 KB in size.
Region: All the resources were created in aws us-east-1, and API calls were made from 2 EC2 nodes in the same region.
Lambda Memory size = 1024 MB
Lambda execution time with DynamoDB backend
I simulated 500 users making the API call with a ramp-up period of 30 secs hitting two separate GraphQL endpoints (one with DynamoDB and the other one with PostgreSQL). All the 500 users posted the same payload; there is no caching involved for this analysis.
The service map below was created by AWS X-Ray:

For 99% of the simulated calls, DynamoDB took less than 15ms; but 1% of the calls had high response times which resulted in overall avg latency of 25ms. The Lambda execution time was 60ms; the time spent on the Lambda service itself was 90ms on average (we can optimize the Lambda execution time, but not service time itself).
Cold Starts
Approximately 2% of the total calls were cold starts. I noticed an additional latency of 700ms-800ms in Lambda execution time for the first API call, which came from initialization of the Lambda container itself.
This additional latency was observed in both endpoints (DynamoDB and PostgreSQL). There are ways to optimize this overhead, and I would strongly recommend you to read up on them here.
Increase in Lambda memory size limit by 2x and 3x
Increasing the lambda memory size by 2x (2048 MB) improved the overall latency of the Lambda service by 18%; increasing by 3x (3008 MB) improved the latency by 38%.
The latency of DynamoDB backend remained constant, and the Lambda execution time itself improved within 20% range for 3x memory:
Lambda Service Latency (1GB Memory) | Lambda Service Latency (2GB Memory) :-------------------------:|:-------------------------:  |
| 
Lambda execution time with PostgreSQL backend
With RDS, the Lambda execution time increased along with the size of the data.
When I increased the Tweets dataset by a factor of 100 (to 1000 tweets per user), I found the response time increased by 5x-10x. This possibly happens because we are joining the Tweets and Users tables on the fly, which results in more query execution time.
Query performance can be further improved by using indexing and other database optimizations. Conversely, DynamoDB latency remains constant with increasing dataset size (which is expected by design).
API Gateway and Network Latency
On average, the E2E response time of the GraphQL endpoint ranges from 100ms-200ms (including the Lambda execution time). Hence, on API Gateway the network latency is approximately between 40-100 ms, which can be further reduced by caching.
You might ask, "Why do we need API Gateway? Can't we just use Lambda to fetch the GraphQL response?"
Well. This analysis truly merits a separate blog of its own, where we can do an in-depth study of all the latencies and query optimizations. Or you can also read this forum discussion about it.
Selling GraphQL in your organization
When using new tech, always a discussion of “do we want this, or not?”
Ready to switch everything over, but not sure about how to convince the backend team? Well, here’s how I’ve seen this play out several times, with success.
First, the frontend team would wrap their existing REST APIs in a serverless GraphQL endpoint. It added some latency, but they were able to experiment with product changes way faster and could fetch only what was needed.
Then, they would use this superior workflow to gain even more buy-in. They would back up this buy-in by showing the backend team that nothing had broken so far.
Now I’m not saying you should do that, but also, if you wanted to, there it is for your consideration. My lips are sealed.
Special thanks!
First of all, I would like to thank Nik Graf, Philipp Müns and Austen Collins for kickstarting open source initiatives to help people build GraphQL endpoints easily on Serverless platforms. I have personally learned a lot during my work with you guys!
I would also like to give a shout to our open source committers - Jon, Léo Pradel, Tim, Justin, Dan Kreiger and others.
Thanks Andrea and Drake Costa for reviewing the final draft of this post and Rich for helping me out with questions.
Last but not the least, I would like to thank Steven for introducing me to GraphQL.
I hope you guys liked my first blog post! Feel free to reach out and let me know what you think.
Siddharth Gupta