I’ve spent the last 5+ years, first at CircleCI and now at Serverless, talking with technology decision makers about their cloud adoption strategies. The number one concern that I hear today, that I rarely heard five years ago, is the organizational requirement for vendor choice.
In the early days of the cloud, the primary concern was vendor lock-in. Many organizations saw relying on third parties for their application infrastructure as a relatively new, and overly risky, pattern. But the world has changed quite a bit since those early days.
Now we have a highly digitized economy that values speed. We have a multitude of developer services—AWS, Google, Microsoft, Stripe, Auth0, Cloudflare—who are releasing new products and features all the time. These products and features promise even more speed, even faster iteration.
The serverless movement itself has produced countless success stories showing that small teams, using highly abstracted services like AWS Lambda, can innovate and ship software at an incredible rate. I'm seeing greater interest than ever in speed and efficiency, even at the expense of lock-in.
So no, the question is no longer about vendor lock-in. It is about vendor choice. How do organizations remain agile and fast, remain able to utilize the best developer tooling to accelerate past what was previously thought possible?

Vendor choice is one of the most important things IT decision-makers could be thinking about today. And the path to achieving it, I believe, is data portability.
How vendor choice is different than lock-in
Organizations that favor speed and efficiency above all else are increasingly adopting a serverless approach to their application architecture. And in tandem, they’re thinking about the need to optimize for vendor choice.
This may seem the same as avoiding lock-in, but the mindset is actually quite different. Vendor choice means achieving a state in which engineers (and the organization as a whole) have as much flexibility as possible in choosing the tools they need to solve the problem at hand.
Many serverless architectures are not simply AWS Lambda in tandem with some other AWS services, but a mesh of other services—Stripe for handling payments, Okta for handling user authentication, and Twilio for sending SMS.
Different tools are more appropriate for different use cases, and vendor choice is about having the flexibility to select these tools on a use case by use case basis.
Failing to achieve vendor choice and it’s costs
In my experience, any approach that limits an organization to a single platform has high costs, particularly in regards to speed and efficiency. The market simply moves too fast to be limited by a single platform.
Technology leaders from companies like Expedia, JPMorgan and Coca-Cola have all talked openly about their pursuit of vendor choice, and the flexibility and agility that it gives them. I predict that these stories will become more common in the coming years, and further, that technology leaders who are able to achieve vendor choice will put their organization in a position to win. They will get software to market faster, deliver greater levels of innovation, reduce operational costs, and retain better talent.

Acknowledging the real problem: data lock-in
The true danger with lock-in, especially with serverless, is the potential for data lock-in. Data has gravity. It accumulates. Data is economically disincentivized to leave, by way of platform pricing. This is the single biggest threat to vendor choice.
Lambda, for example, provides a ton of value to developers, but it only integrates natively with AWS-specific storage options like DynamoDB and S3. Auth0 gives you powerful user authentication out of the box, but results in your user data being stuck in a closed system. Stripe let’s you accept digital payments in minutes, but results in very valuable payment and customer information tethered to a paid service.
Being locked in to these services and their ecosystems is a byproduct of the fact that our data is locked in to these services.
The path to vendor choice
The serverless movement is an important step toward the ultimate dream—a world in which developers can focus only on honing and improving their secret sauce, while 3rd party services take care of the rest.
But how can organizations move toward this, while also maintaining vendor choice? The answer lies in data portability.

Data portability means that organizations can move their data anywhere they want, whenever they want. This allows them to switch out their managed services at any time, or use several different competing services in tandem. It’s a best of both worlds scenario: organizations get the increased efficiency they want from managed services, while also maintaining autonomy over their own data.
Obviously, however, most vendors are not going to be incentivized to make their data portable. Lock-in benefits them (at least in the short term) by helping them retain customers. To achieve true data portability, and therefore enable vendor choice, we need to champion external solutions.
Open source may be the solution
There are many open source efforts underway that have the specific goal of granting more flexibility and choice when it comes to data.
One such effort is CloudEvents, which is currently incubated within the CNCF. The goal of CloudEvents is to create an open spec for describing event data. This effort will make data, in the form of events, much more portable between cloud providers.

If 3rd party providers all speak and understand the same event format, developers can easily move data between them. This goes a long way toward solving the current challenges that exist with data lock-in.
A second effort, led by our team here at Serverless Inc., is Event Gateway—an open source event router. It sits above the various clouds and services in your architecture, and allows developers to route data in the form of events to any compute they want.
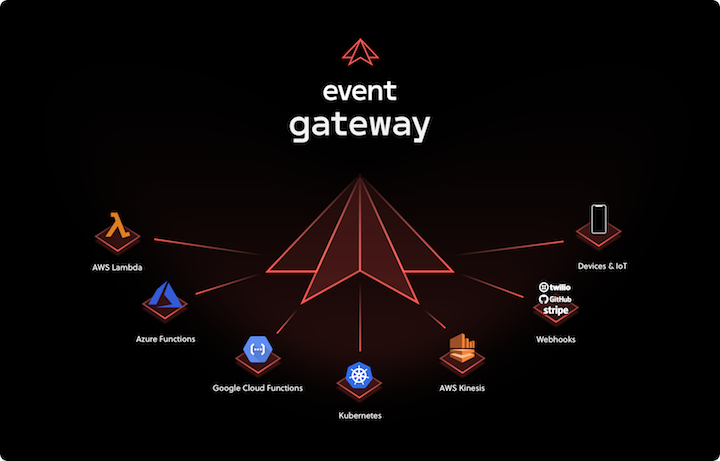
Using Event Gateway, developers can (for example) route events from an AWS S3 bucket to a TensorFlow service on Google Cloud Platform, and then store the results in a hosted big data platform. Or, they can react to events from a database on Azure with AWS Lambda.
These are just a couple examples of workflows that could be highly valuable but are nearly impossible to achieve with the tools available today. The serverless movement, and its vision of extreme developer productivity, is still in its early stages. It will not be able to reach its full potential, however, unless we figure out a way to avoid data lock-in and push for vendor choice.
(Photo credit to Joshua Sortino & Alexandre Godreau)