At re:Invent 2018, AWS announced DynamoDB On-Demand. This lets you pay for DynamoDB on a per-request basis rather than planning capacity ahead of time.
We at Serverless are really excited about this new pricing model and can't wait to use it in our applications. This post is your one-stop-shop on all things DynamoDB On-Demand + Serverless.
In this post, we'll cover:
- What is DynamoDB On-Demand
- How do I use DynamoDB On-Demand in my Serverless applications
- When does it make sense to use DynamoDB On-Demand
- Other facts and questions about DynamoDB On-Demand
- Can I use it with my existing tables?
- How does this compare with reserved capacity?
- What does this mean for hot partitions?
- Are there any limits?
Let's get started!
What is DynamoDB On-Demand?
DynamoDB On-Demand is a new pricing model for DynamoDB.
Previously, you had to set read and write throughput capacity on your DynamoDB tables. This specified how many and how large of reads and writes you could make on your table in any given second. Read and write capacity units were charged by the hour, and your requests would be throttled if you exceeded your provisioned capacity in any given second.
The throttles could be an annoyance, particularly for Serverless developers. The whole premise of Serverless is based on auto-scaling, pay-per-use so that I don't have to think or care about capacity planning ahead of time.
Yet there I was, trying to predict how many kilobytes of reads per second I would need at peak to make sure I wouldn't be throttling my users. In 2017, DynamoDB added Auto-Scaling which helped with this problem, but scaling was a delayed process and didn't address the core issues.
With DynamoDB On-Demand, capacity planning is a thing of the past. You don't specify read and write capacity at all—you pay only for usage of your DynamoDB tables. This fits perfectly with the Lambda and Serverless model—I pay more when I have more usage, which means I'm delivering more value to my customers.
Now that you know that DynamoDB On-Demand is a great fit with your Serverless applications, let's see how you can use it with the Serverless Framework.
How do I use DynamoDB On-Demand in my Serverless applications
(First of all, huge props to Doug Tangren for publishing a guide on how to do this with the Serverless Framework!)
If you're using DynamoDB tables in your Serverless Framework applications, you're likely managing your tables using infrastructure-as-code in the resources block of your serverless.yml file.
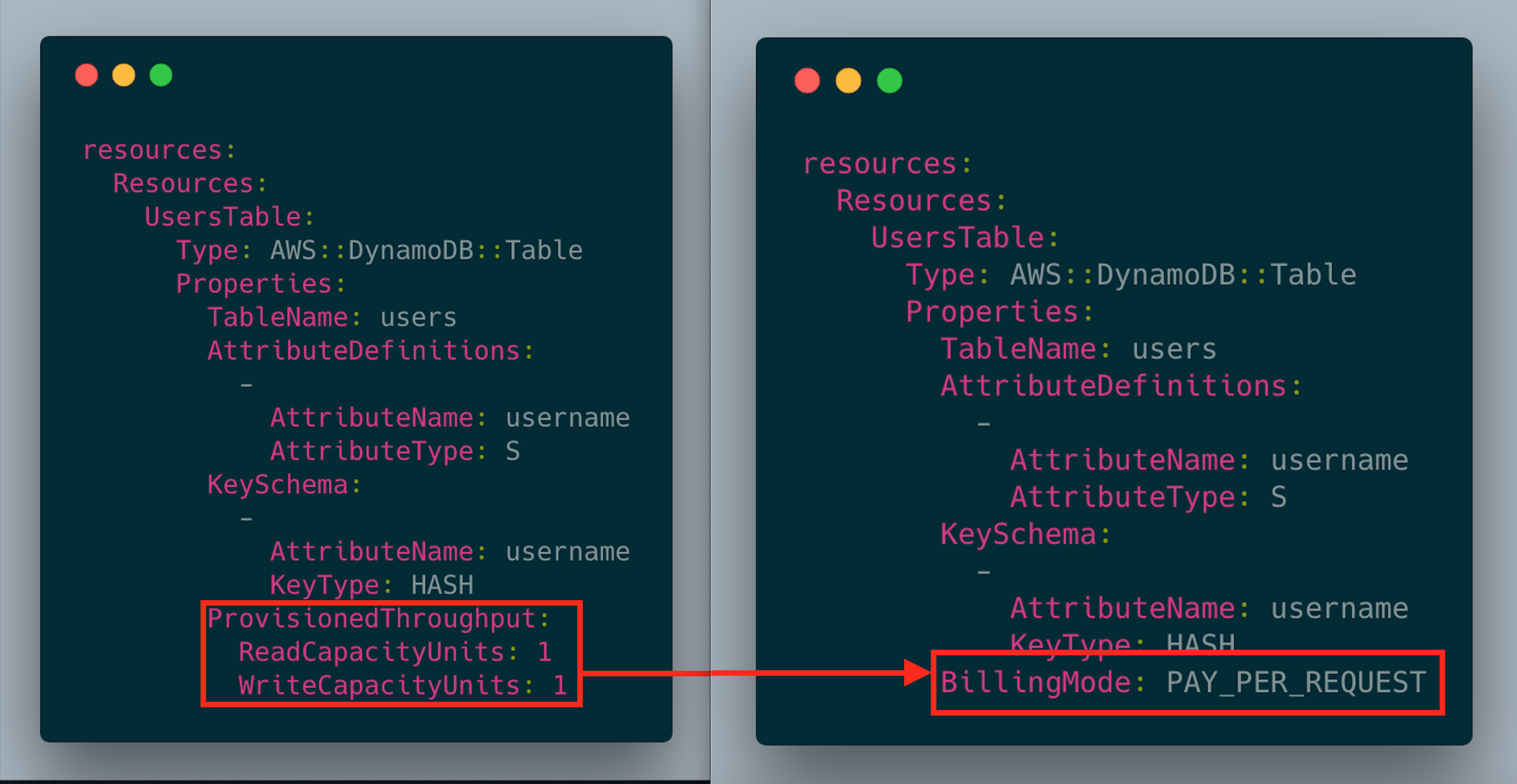
To move from provisioned capacity to on-demand pricing, you need to do two things:
-
Remove the
ProvisionedThroughputsection of your DynamoDB table. If you're using any Global Secondary Indexes, you should also remove theProvisionedThroughputsection of your indexes. -
Add
BillingMode: PAY_PER_REQUESTto your table.
That's it! Below is an example of how your table will change:
For a starter that you can copy and paste into your serverless.yml, use the block below:
resources:
Resources:
UsersTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: users
AttributeDefinitions:
-
AttributeName: username
AttributeType: S
KeySchema:
-
AttributeName: username
KeyType: HASH
BillingMode: PAY_PER_REQUEST
When does it make sense to use DynamoDB On-Demand
DynamoDB On-Demand is a great step forward, and I'm excited to not have to think about capacity-planning for my databases anymore. That said, there may be times when you want to use the traditional provisioned mode.
In general, there are two reasons why you may want to use DynamoDB provisioned pricing rather than on-demand pricing:
- You can predict your traffic patterns pretty well.
- You are worried about a runaway bill. This is pretty rare, so see comments below.
You have predictable traffic patterns
If your applications have predictable traffic patterns and you don't mind spending the time to understand those patterns, using DynamoDB's provisioned throughput capacity can save you money. Let's walk through some basics on DynamoDB pricing and then do some simple math.
DynamoDB charges in terms of read and write request units. A read request unit lets you read 4KB of data in a strongly-consistent way. A write request unit lets you write 1KB of data in a standard way.
Note: There's additional nuance both in read requests units (strongly-consistent vs. eventually-consistent) and in write request units (standard vs. transactional). The math ends up similar, so we'll skip the complexity.
With on-demand pricing, you pay directly based on the requests you use. In us-east-1, on-demand pricing costs $1.25 per million write request units and $0.25 per million read requests units.
With provisioned throughput, you pay based on having the capacity to handle a given amount of read and write throughput. You pay for read and write capacity units. Each read capacity unit allows you to handle one read request per second and each write capacity unit allows you to handle one write request per second.
Read and write capacity units are both charged on an hourly basis. In us-east-1, read capacity units cost $0.00013 per hour and write capacity units cost $0.00065 per hour.
If we normalize the capacity units to a 30-day month, a read capacity unit costs $0.09 per month and a write capacity unit costs $0.47 per month.
If you fully utilized your capacity units, each unit would give you 2,592,000 requests in a 30-day month. With this full utilization, you would be paying $0.036 per 1 million read requests and $0.18 per 1 million write requests.
Thus, DynamoDB On-Demand pricing is about 6.94x the cost of provisioned capacity.
However, it's highly unlikely you are fully-utilizing your provisioned capacity units. This difference in pricing is the maximum difference if you're working at peak capacity. It would be near impossible for you to have 100% utilization of your read and write capacity units for every second of a month.
That being said, if you have predictable patterns and can stay at 40%+ utilization over a month with low maintenance around it, using provisioned throughput can be the right move for you. This is even more true if you utilize reserved capacity to knock down the provisioned throughput pricing even further.
You have concerns about a runaway bill
For the FUD crowd out there, it is possible that on-demand billing could result in an unexpected bill spike. If you have a huge spike in DynamoDB requests due to a spike in your application's popularity, it's possible that you will pay much more in DynamoDB costs than if you were using provisioned throughput.
With provisioned throughput, you're essentially putting a cap on how much you will spend on your DynamoDB table. Your users will pay the price with throttling.
With on-demand, your bill could be unexpectedly high but you won't be making your users pay the price with a poor experience.
Ultimately, having happy users should be more important than short-term budget fluctuations. If you are worried about runaway costs, there are better ways to handle it than capping it via provisioned throughput.
Other facts and questions about DynamoDB On-Demand
Here are some other commonly-asked questions about DynamoDB On-Demand:
Can I use it with my existing tables?
Yep! You can switch your tables over to it right now. You can do this in your serverless.yml as shown above.
You can also do it in the AWS console (but you really shouldn't do it in the console—use infrastructure-as-code!):

How does this interact with reserved capacity?
With DynamoDB's provisioned capacity, you can use reserved capacity. With reserved capacity, you pre-pay for a certain amount of provisioned capacity. In return, you get a lower price. It is similar to Reserved Instances with AWS EC2.
At this point, you cannot use reserved capacity with DynamoDB On-Demand. It is a feature of provisioned capacity only.
With so many options—reserved capacity, provisioned capacity, on-demand—how do you know which pricing option is right for you? Here's a quick guide:
- If you have steady, predictable traffic, choose reserved capacity. Since you know you need a certain amount of capacity at all times, you can save from reduced rates.
- If you have variable, predictable traffic, choose provisioned capacity. Imagine you have significant traffic during the day but no traffic overnight. Reserved capacity would be wasted overnight, but your patterns are predictable enough that you could scale up your provisioned capacity when you need it.
- If you have variable, unpredictable traffic, choose on-demand. If your application gets random spikes, it can be hard to provision capacity to match demand. Use the on-demand feature so you don't throttle your users.
What if you don't know what bucket you fit into? Just choose on-demand and let AWS handle it for you. Get back to building!
What does this mean for hot partitions?
Over the years, there has been a lot of content around managing DynamoDB's partitions to avoid degraded performance.
For example, you need to avoid hot partitions so that you get the most of your throughput. Or you need to worry about throughput dilution from excessive scaling. So how does DynamoDB On-Demand play with this?
The first thing you need to know is that the partition problems have largely gone away. The DynamoDB team has done a bunch of work behind the scenes around adaptive capacity. This helps adjust to your usage patterns so that additional compute is shifted to hot partitions to avoid resource exhaustion.
From some early tests, it seems like On-Demand has no issues with scaling up and hot partitions. In Danilo Poccia's example with On-Demand, he shows a table that scales from zero to 4,000 write units per second without any throttling!
The rapid, instant scaling of DynamoDB On-Demand is truly impressive and a major feat by the DynamoDB team.
Jim Scharf, the former GM of DynamoDB had a great answer when our own Jared Short asked him how this affects partitions:
Exactly—"Why does it matter?" Partition-planning is basically an unnecessary detail for users.
Are there any limits with DynamoDB On-Demand?
There are a few limits you should know about.
First, there are some limits on how high DynamoDB On-Demand can scale up. By default, that limit is 40,000 read request units and 40,000 write request units per table in most regions. You can increase that if needed. Those numbers are per second, so we're talking some serious traffic.
Second, you are limited in how often you can change between provisioned capacity and on-demand pricing. As of now, it looks like you can only switch once per day.
Conclusion
DynamoDB On-Demand pricing is a huge move forward for Serverless applications and will be the default on all of my tables moving forward. In this guide, we discussed how, when, and why to use it. Now, go build!